最近RAGがどうとかよく聞きますよね。その一環でベクター検索が重宝されてるわけですが、ベクター検索するための下準備が割と面倒くさい感じです。今回はそのあたりを楽にしたいなという話です。
さてAzure上でVector Embeddingしたベクターデータを検索するにはAzure Cognitive Searchなどベクターデータを対象に検索できるDBなりを使うのが一般的かと思います。(他のサービスも機能はあったりしますが今回は触れません)
ここで手間になるのが、一般的なテキストなどのデータと違って事前にベクターデータとしてテキストなどを数値化する必要があるという点です。通常DBなどのストアはこの作業を行いませんので、利用者が変換してあげる必要があります。

ここの図でいうところのTransform into embeddingsの部分とCognitive Searchに入れるところの部分ですね。
またよく利用されるAzure OpenAIなどのEmbedding用LLMはトークン上限があるので1文書のテキスト全部は大きすぎる為、適切なサイズに分割する必要もありわりと面倒です。
世間にはそのあたりを良しなにしてくれるツールはあるのですが、Python環境を用意したりとか本番運用始めると自動実行する部分とかまぁできなくはないけど実装・稼働させるのが面倒だな!というのが多いです。何とかしたいですよね。
というわけで、前置きが長くなりましたがそのあたりの不満を解消できるアップデートがAzure Cognitive Searchに来てそうです、という話です。
AzureOpenAIEmbeddingSkill
まず前提として、Azure Cognitive SearchにはAIエンリッチメントという機能があります。
文書をそのまま解釈してインデックスにするのでなく、スキルセットを使って例えばOCRで図内のテキストを処理したり、翻訳したりなどを行ってよりリッチなインデックスを生成することができます。
エンリッチメントはインデクサーが実施するのですが、インデクサーは定義したCognitive Searchのデータソースからデータを読み取り、スキルセットに処理させて結果をインデックスに追加するというのを行います。

ここからが本題。公式ドキュメントにはまだ追加されていませんが、最近PreviewとしてAzureOpenAIEmbeddingSkillが追加されました。
このスキルセットを使うとAzure OpenAI ServiceのEmbeddingモデルに対してベクター埋め込みをしてくれます!
組み込みスキルセットの テキスト分割コグニティブ スキル を先に実施することで、分割処理+ベクター埋め込みをインデクサーで自動的に処理することができるということですね。
以前はカスタムスキルでベクター埋め込みするFunctionsを呼び出すとかでも対応できたわけですが、それすら不要です。
ということで、その2つを使ったスキルセットを定義できればいいのですが、現時点のAzureポータルはPreview API(2023-10-01-Preview)に対応していないのでエラーになってしまうのでREST API叩くかPreview版のCognitive Search SDKを使う必要があります。
※ Python版もあるみたいですが、PublicになってなさそうでWHL直指定でした。
.NETで上記ベータ版パッケージを使って組んでもいいのですが、Cognitive Searchのベクター関連リポジトリでPython版でこのあたりのスキルセットを使ったJupyter Notebookが公開されているのでそちらを使いました。基本的にREST API呼ぶのと大差ないので、パラメータわかったら.NET版も簡単にできると思います。
せっかくなので、アナライザーを日本語にしたり手直しした版をForkして更新しておいたのでそちらも参考にどうぞ。.env-ja-sample を参考に .env を作ってください。あとPreview版パッケージである whlフォルダーがあれば動くと思います。
インデクサーを作って実行するとベクターデータも追加されたインデックスが作られると思います。

※ chunk_id の末尾にページ番号ぽいのが付与されていますが、元PDFが悪いのか日本語が悪いのかChunkのテキストが含まれるページとズレてるっぽい。。うーん?
最低限これだけしておけば、後はBlobを更新したり追加するだけでベクター埋め込みしたインデックス生成をしてくれる環境ができます。
おまけ
他の方法としてはAzure Machine LearningのPrompt Flow内にベクターインデックスというのもあります。
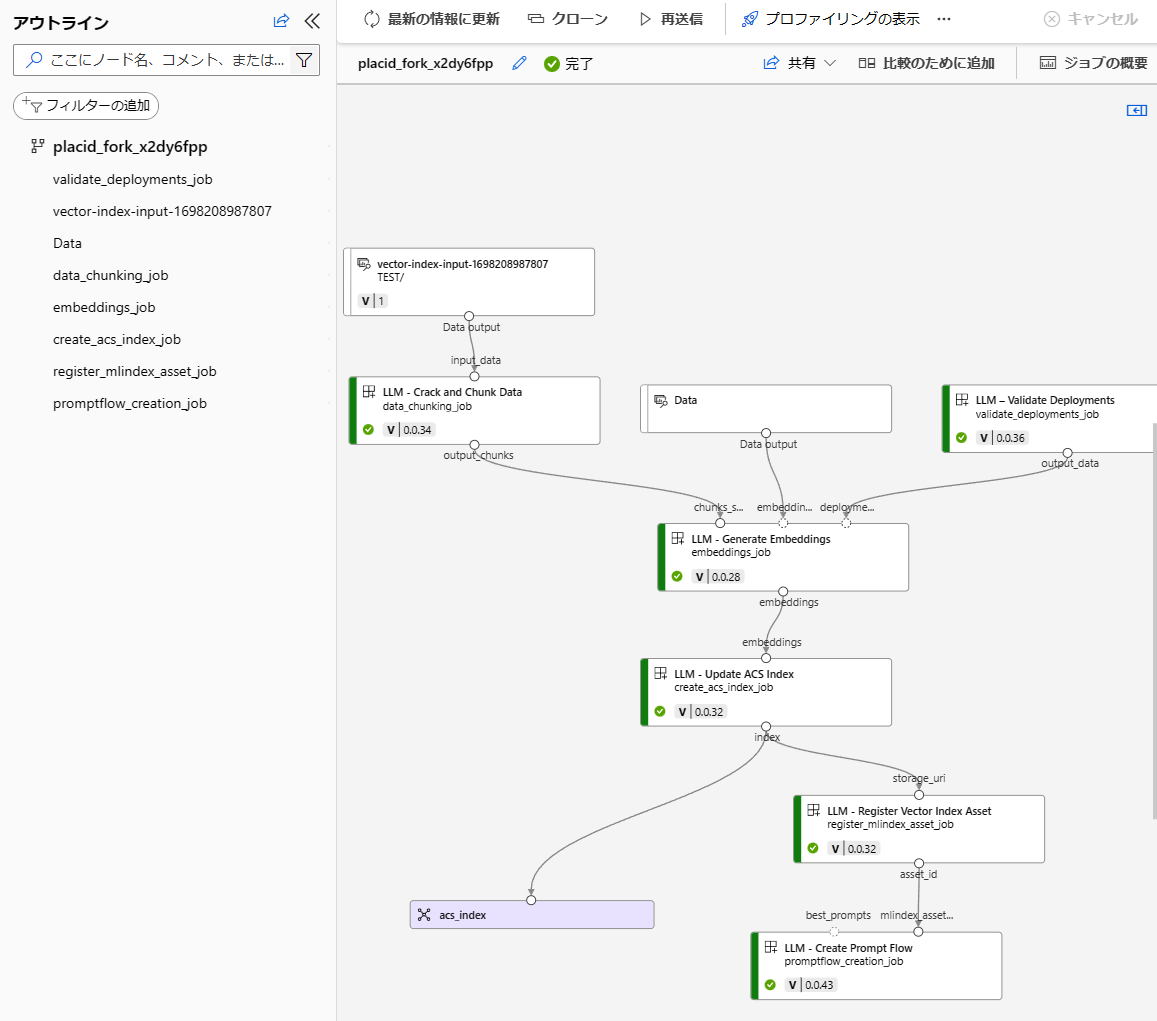
こっちはこっちで割と色々してくれるのと(コード書けるならカスタマイズも出来そう)、Azure Machine Learningのあれこれが使えるのでデータセットの管理など含めて統合的に管理できそうですね。
